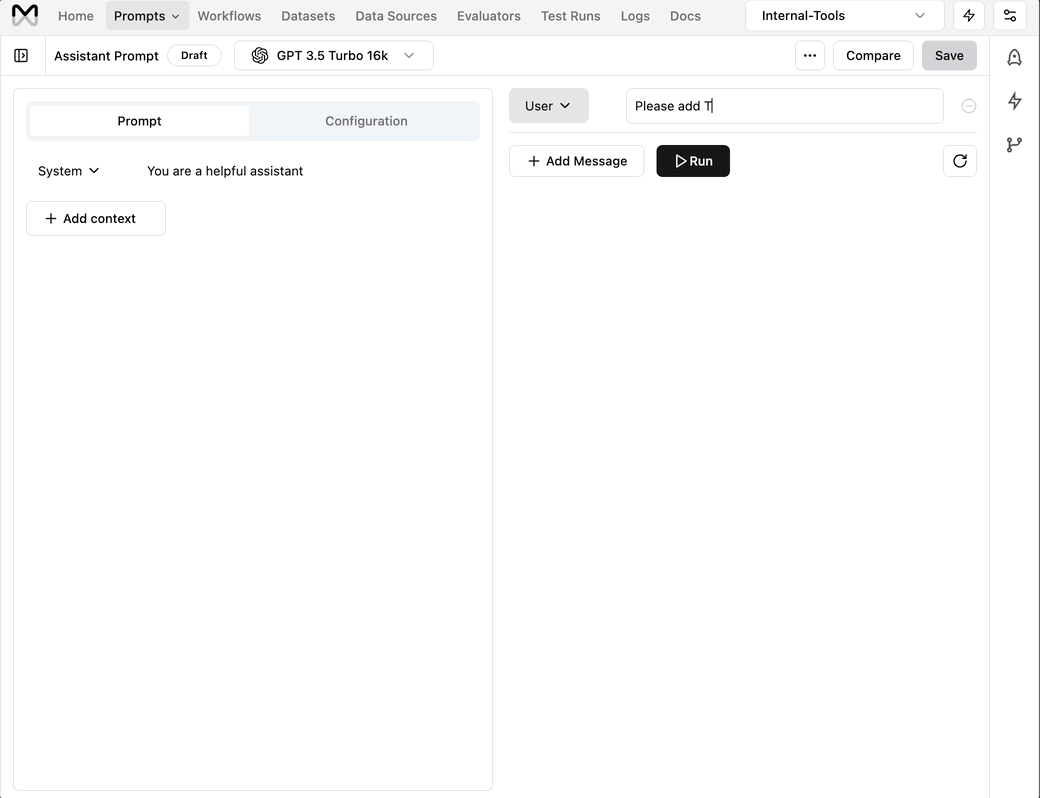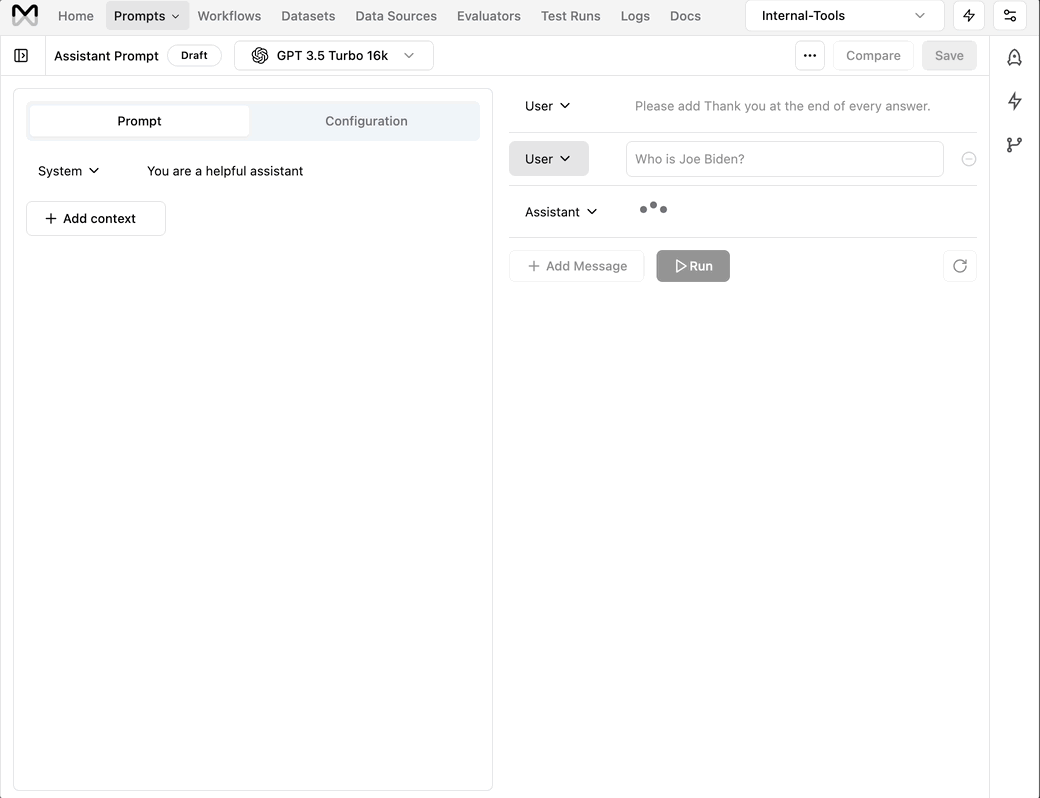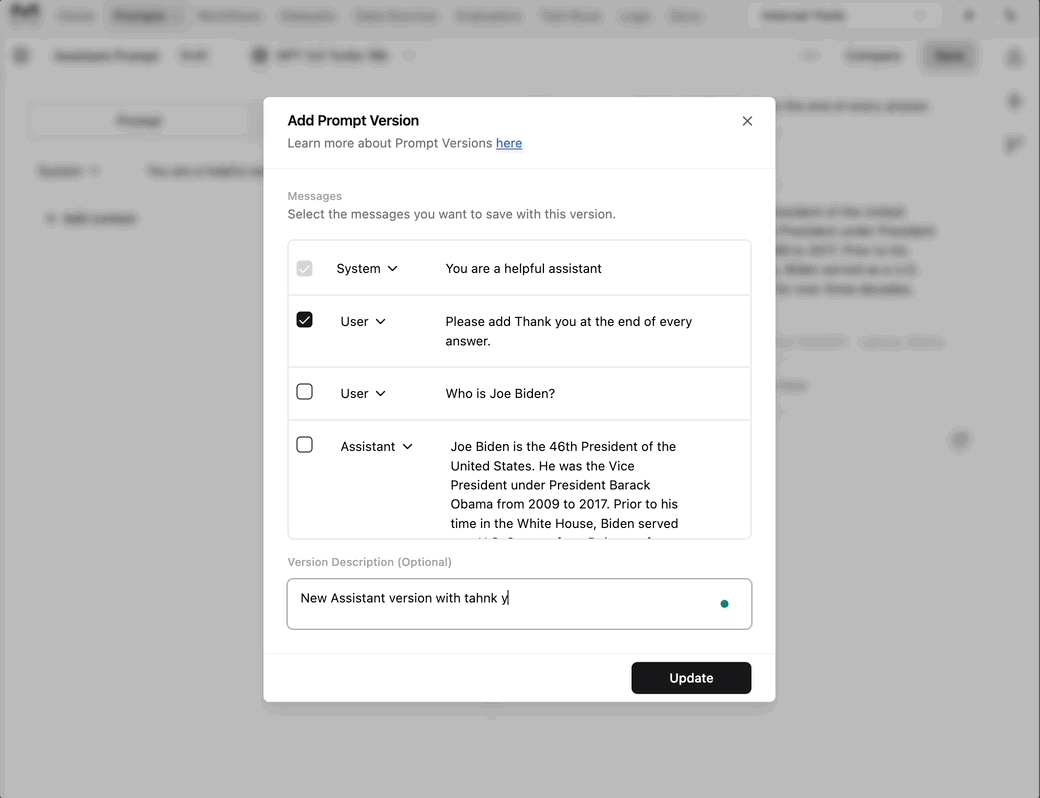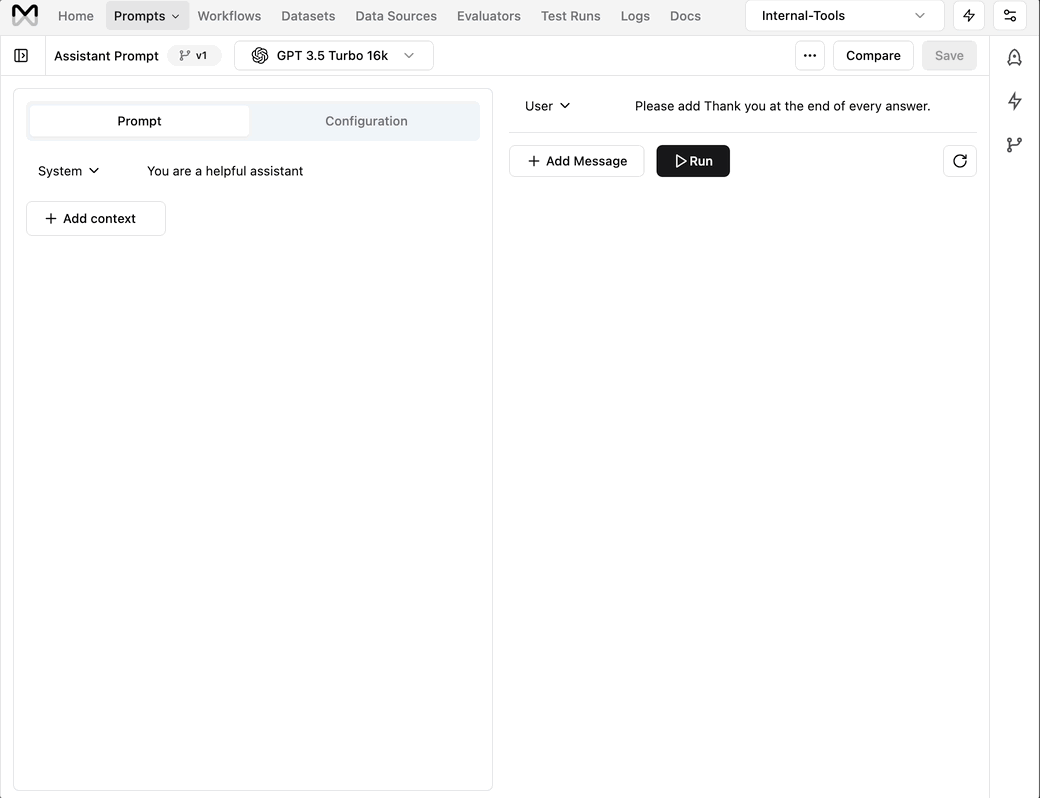
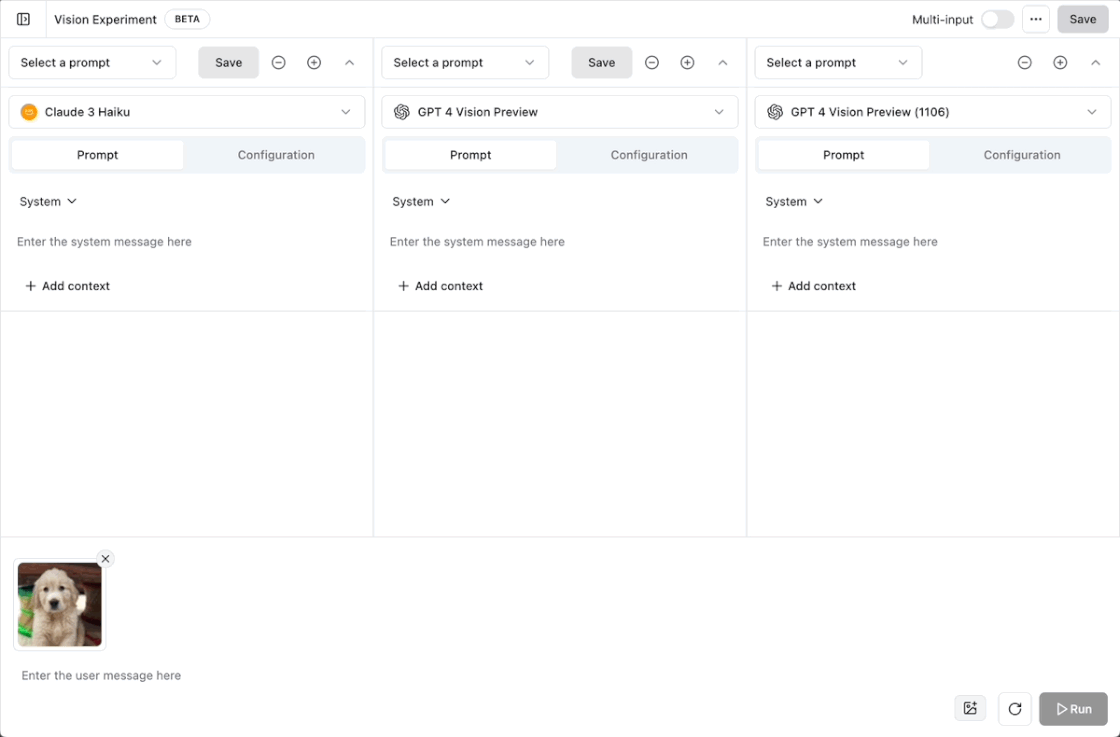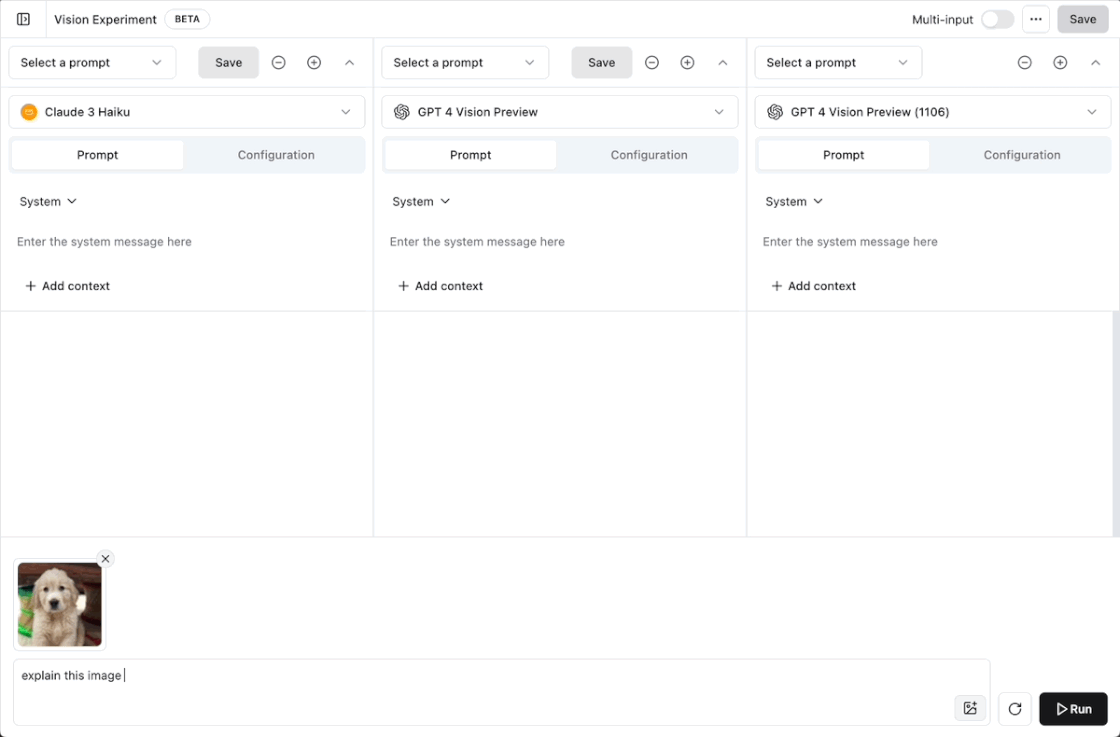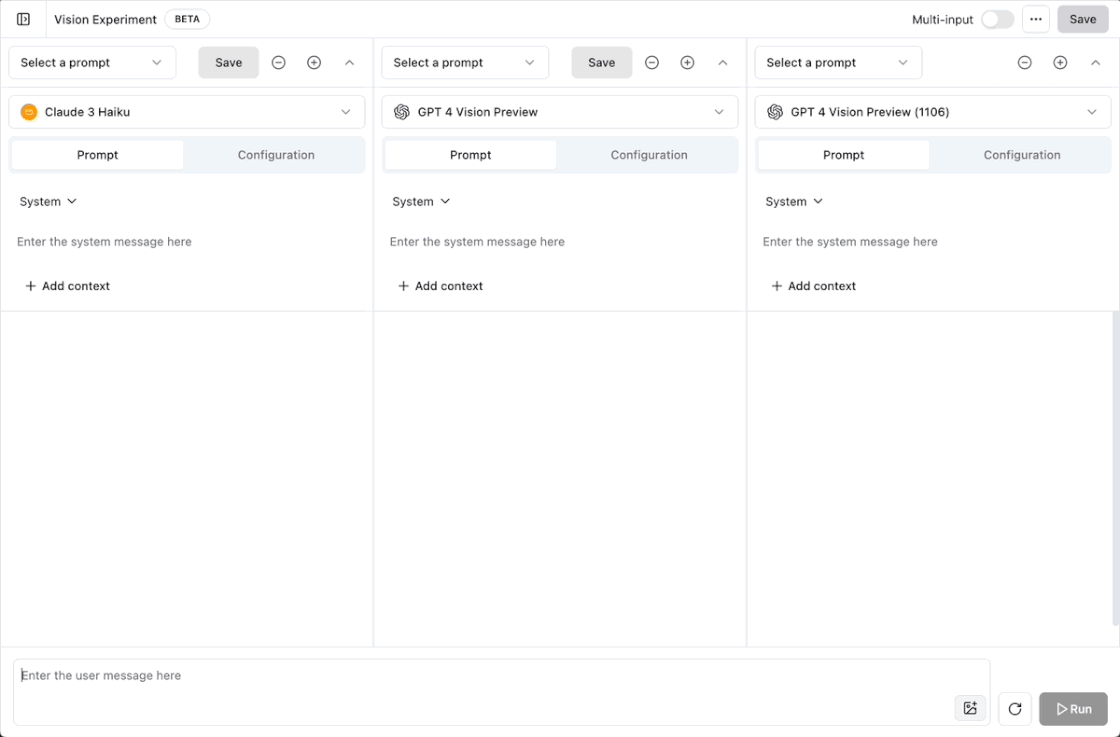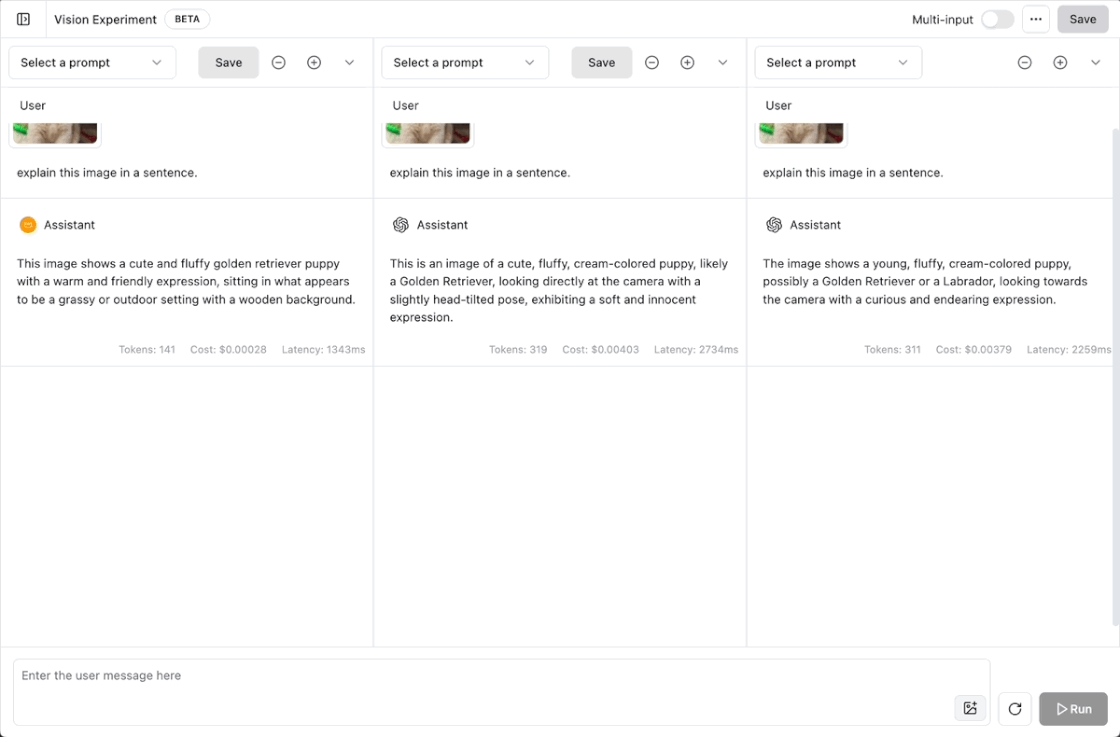
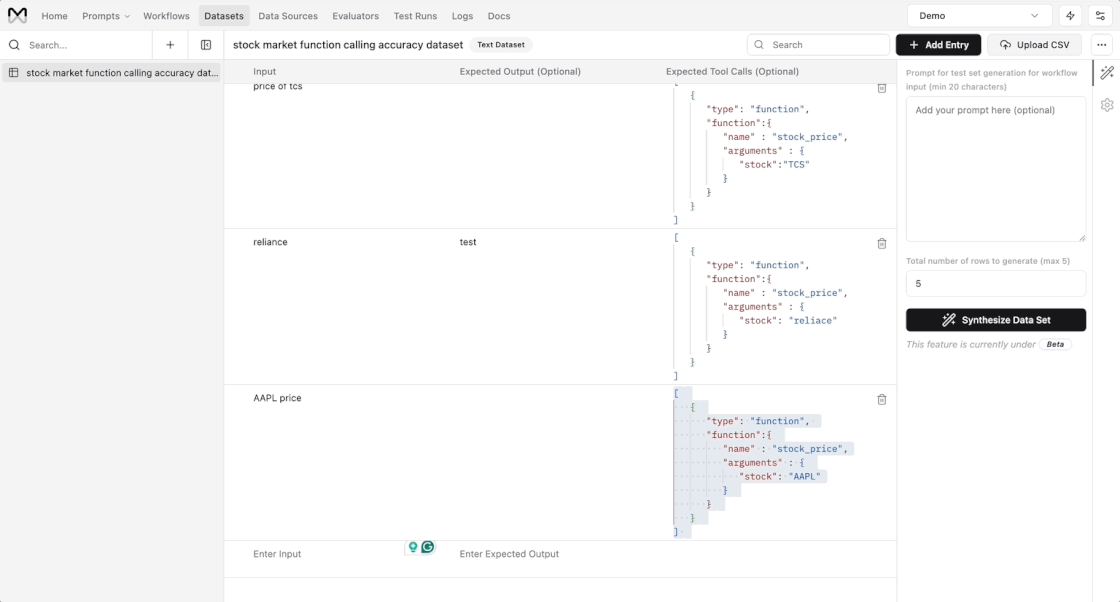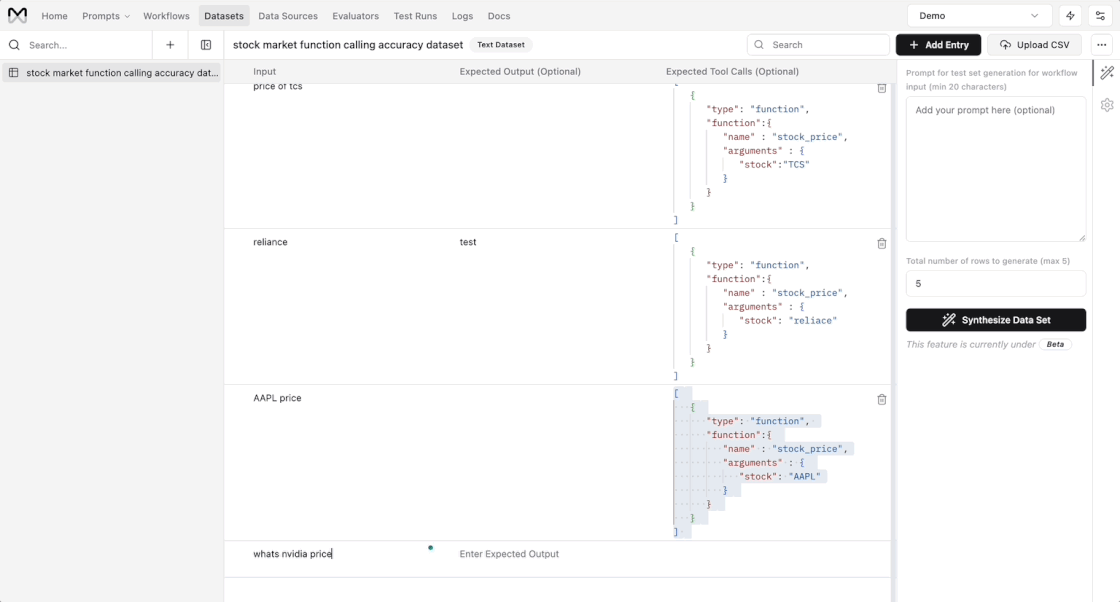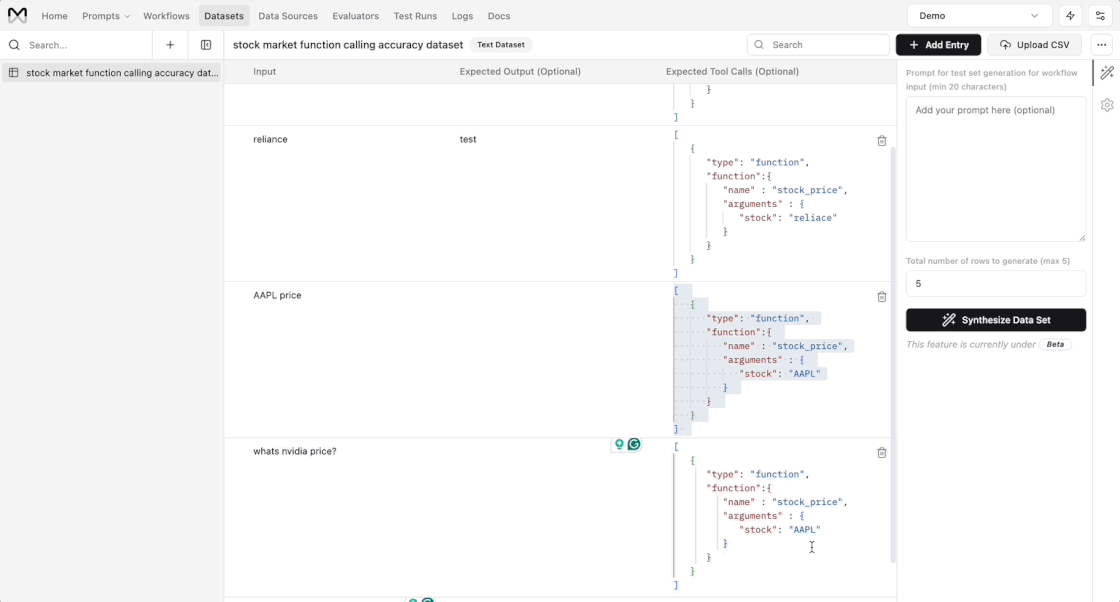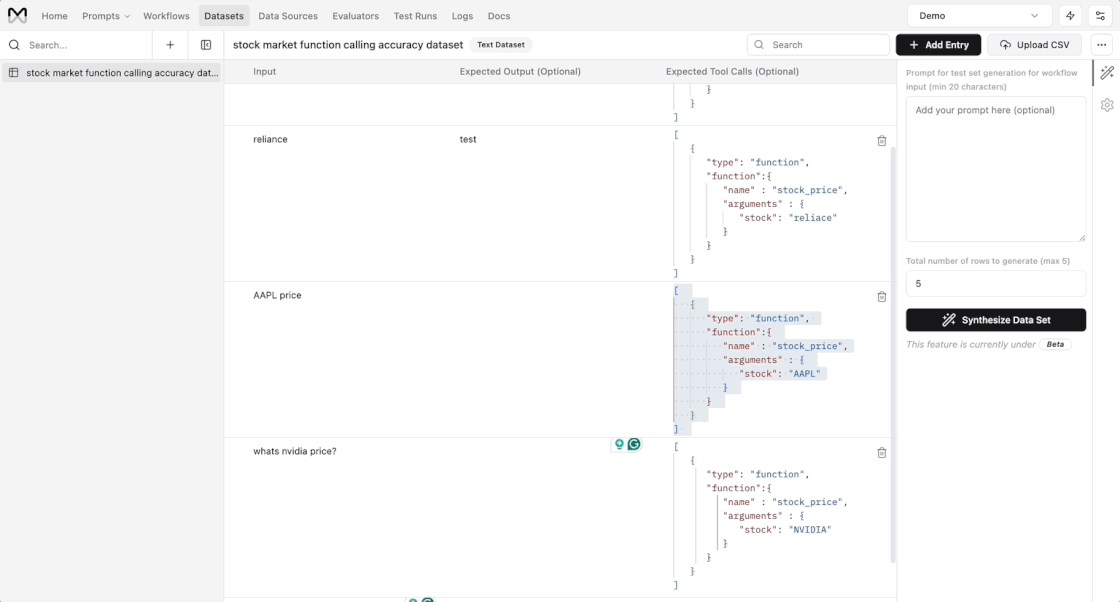
New
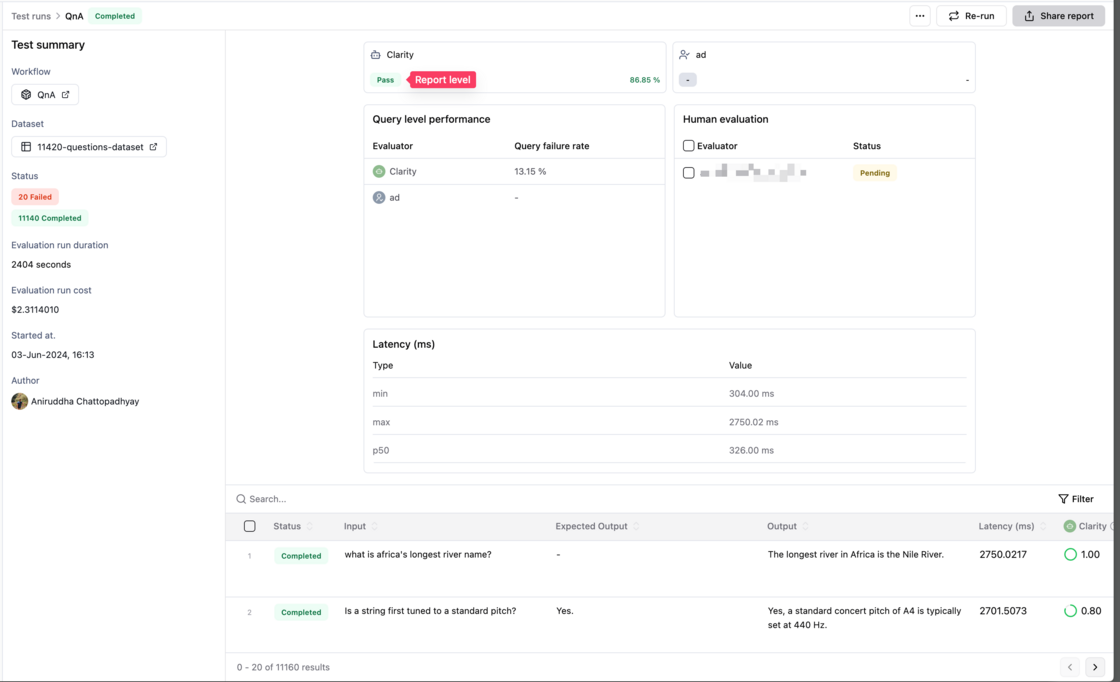
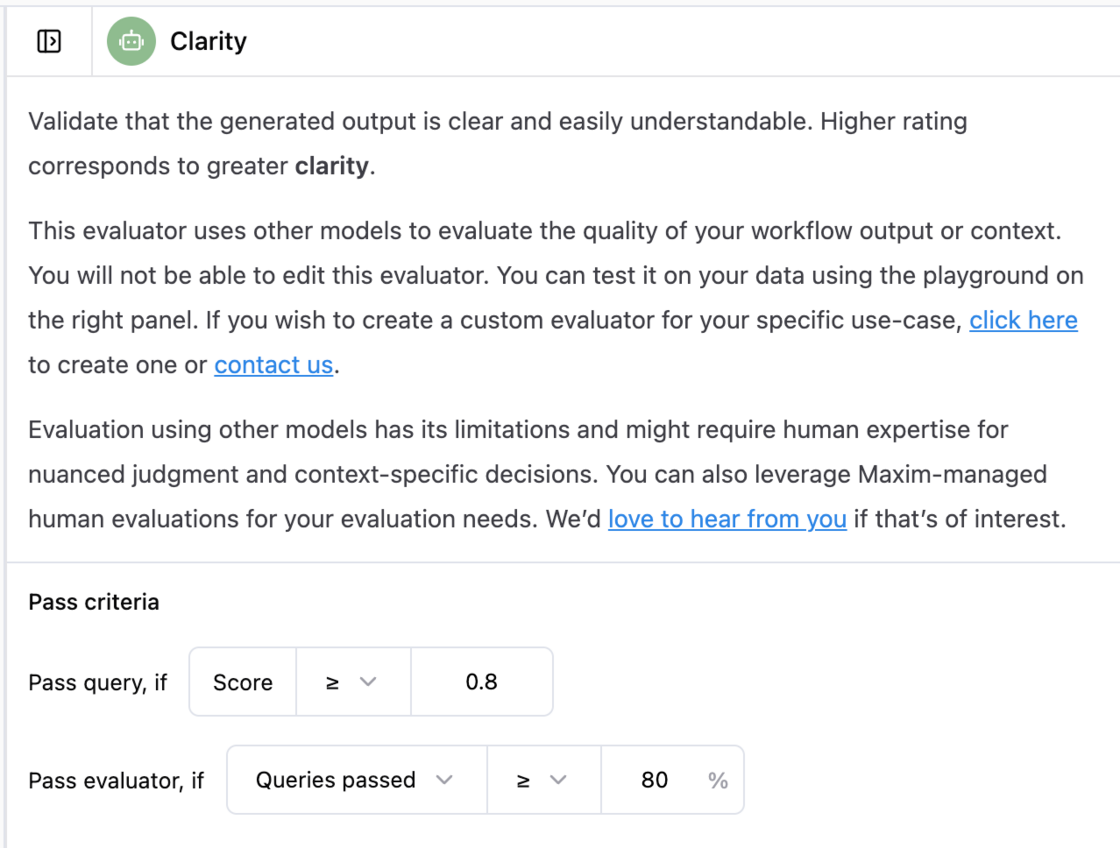
Adding evaluation thresholds is helpful for quick decisions. Today, we are shipping pass-fail workspace-specific criteria on custom and built-in evaluators to speed up decision-making.
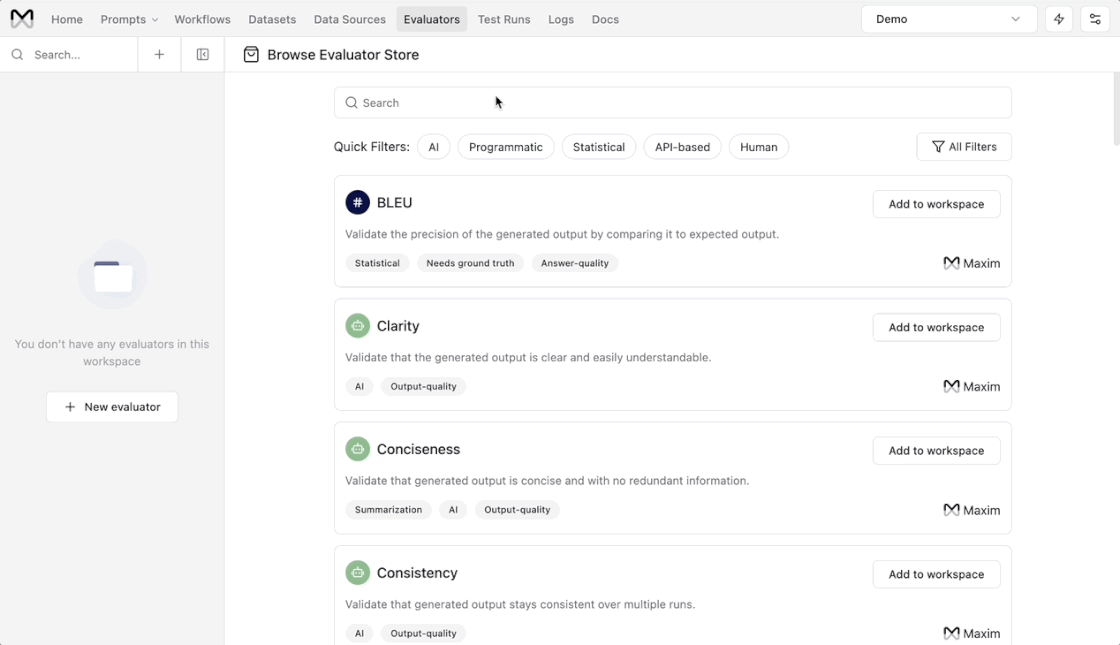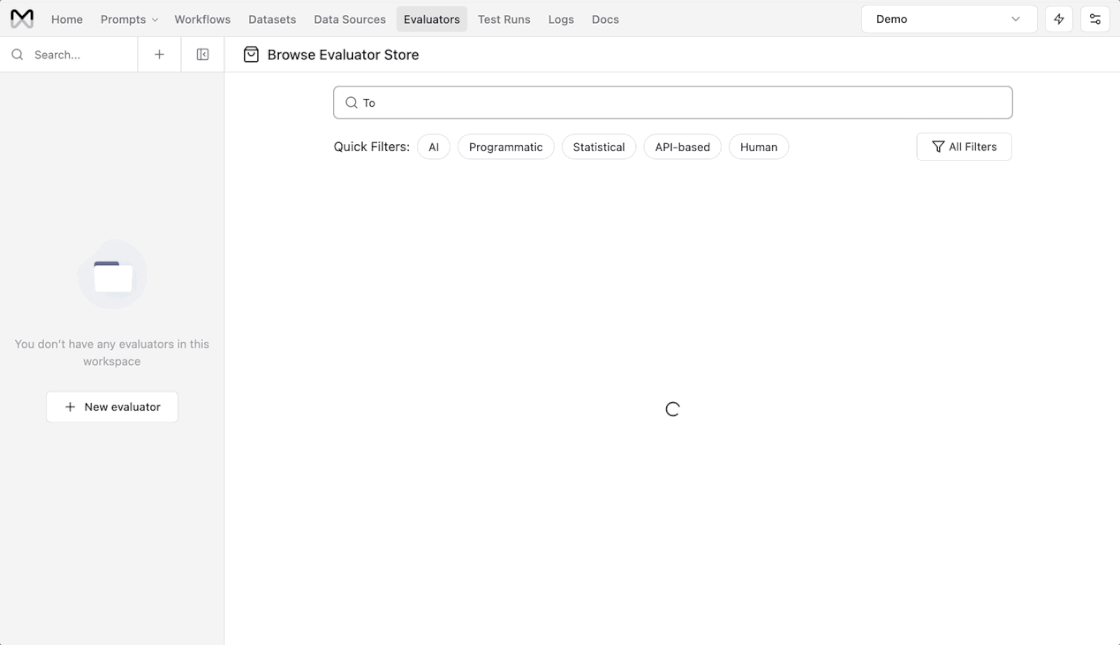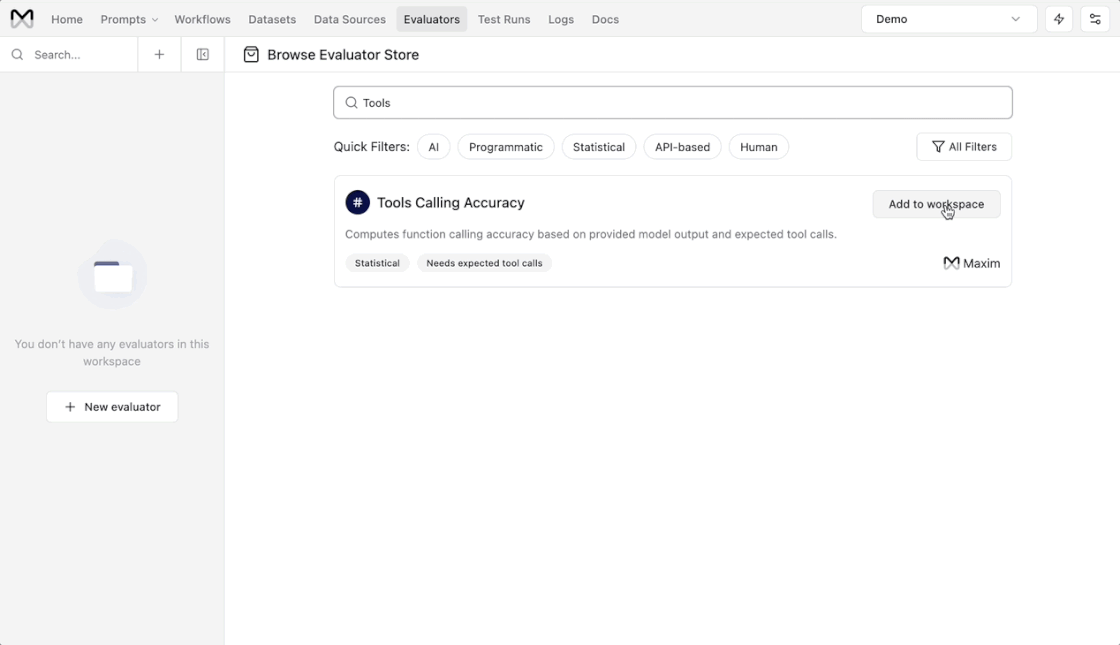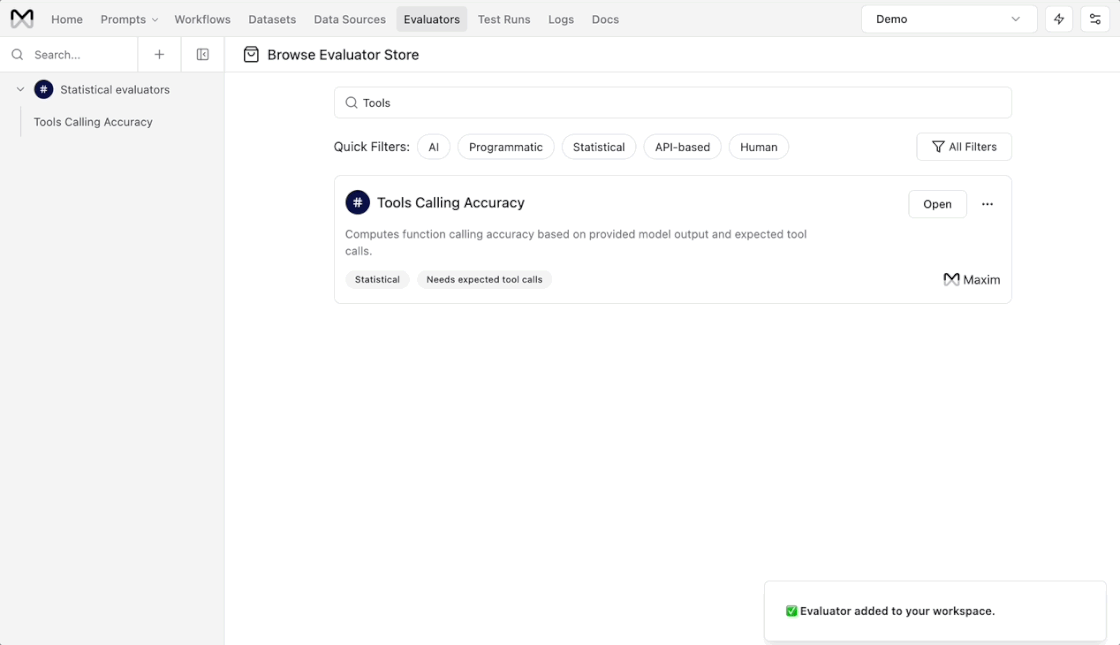
How to set pass-fail criteria?
- Go to any evaluator in your workspace.
- You will see a section called, Pass criteria.
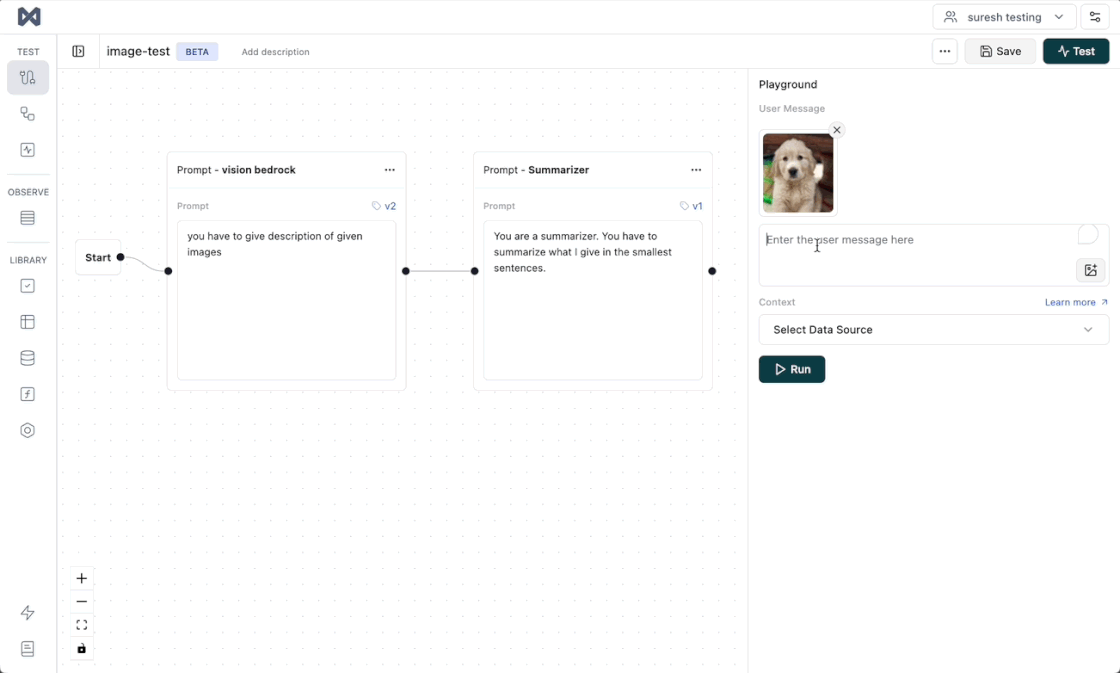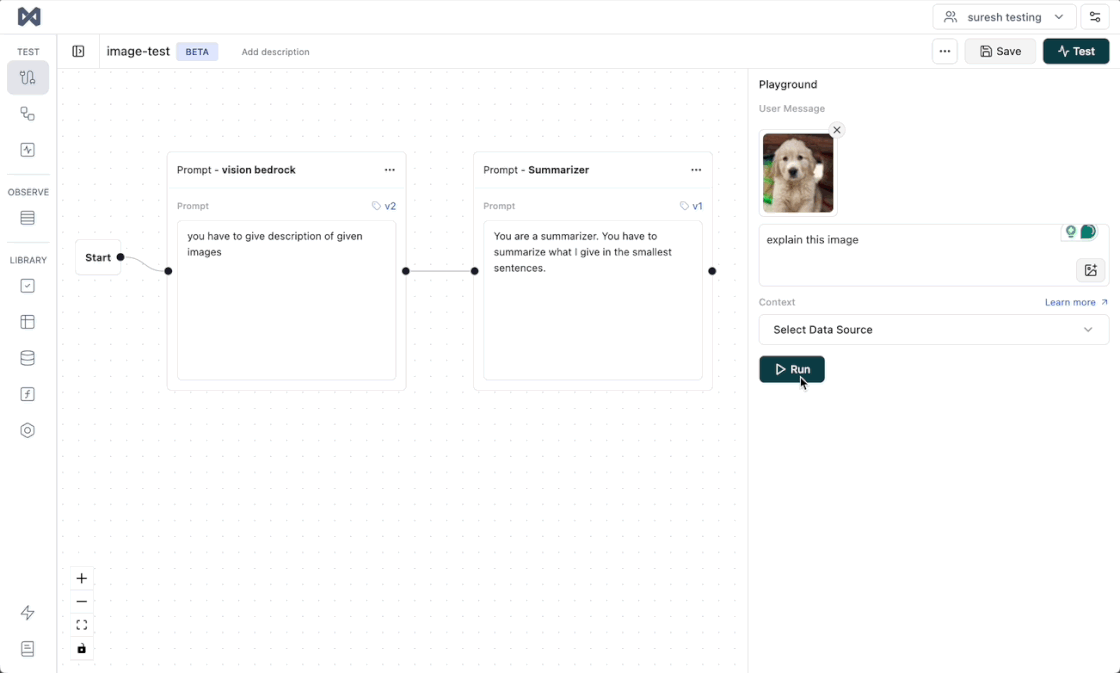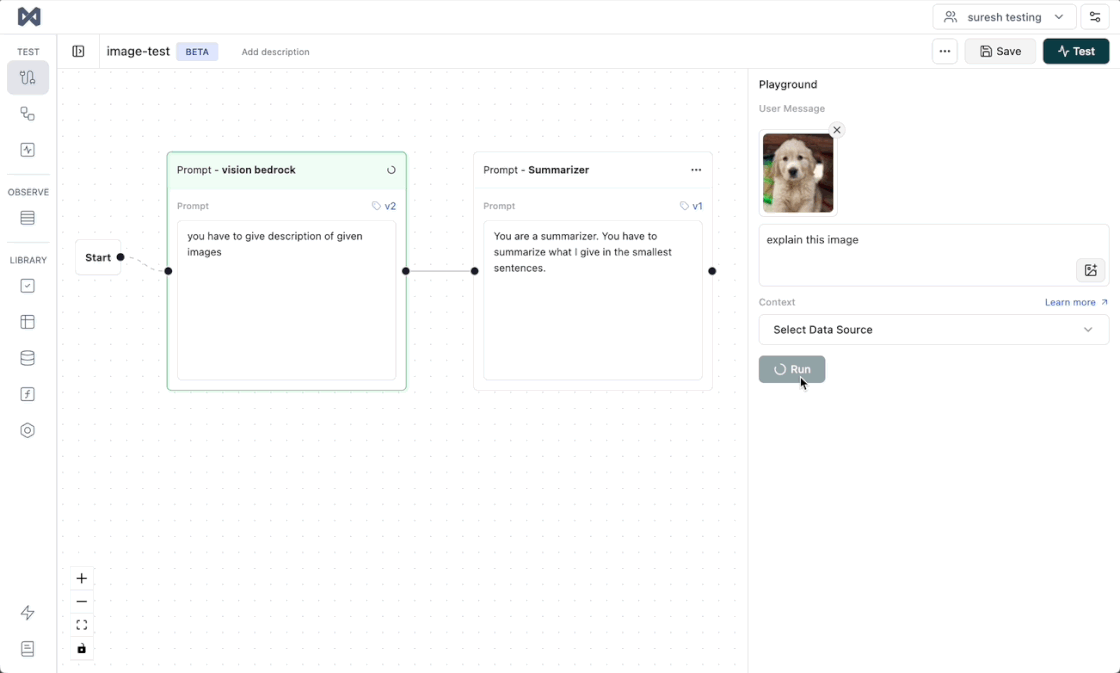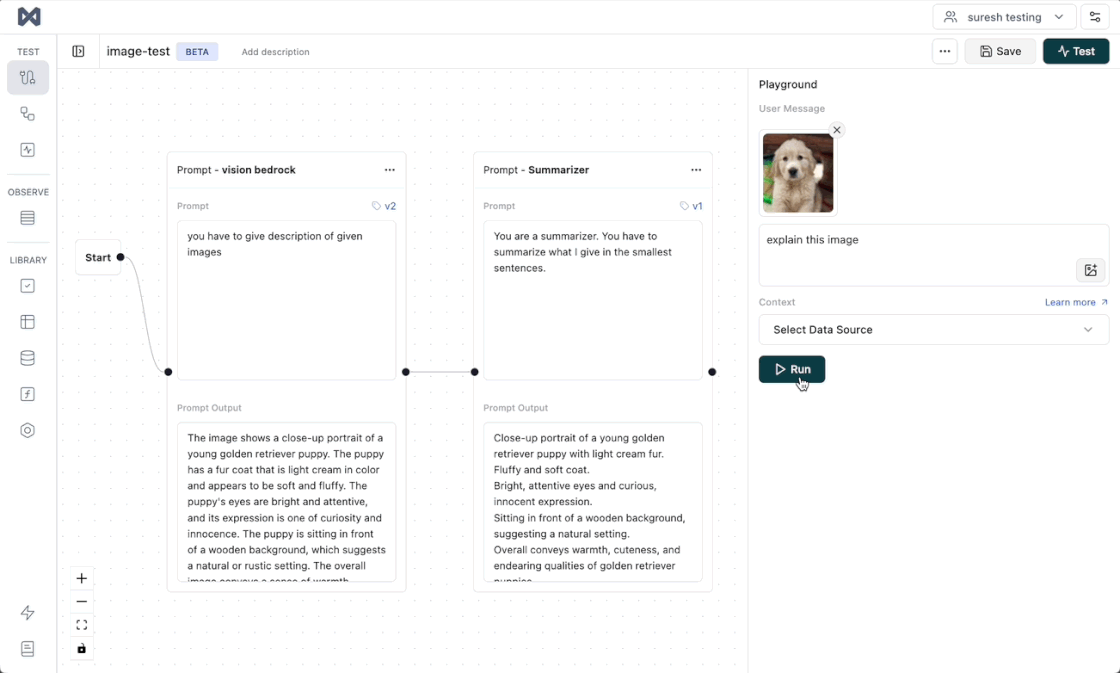
- The first value is on each entry-level i.e. in the given image, a test run entry will be marked as passed, if the "Clarity" score for that test run entry is >= 0.8
- The second value is at the test run report level, i.e., "Clarity" is marked as passed if 80% of the entries are marked as passed.
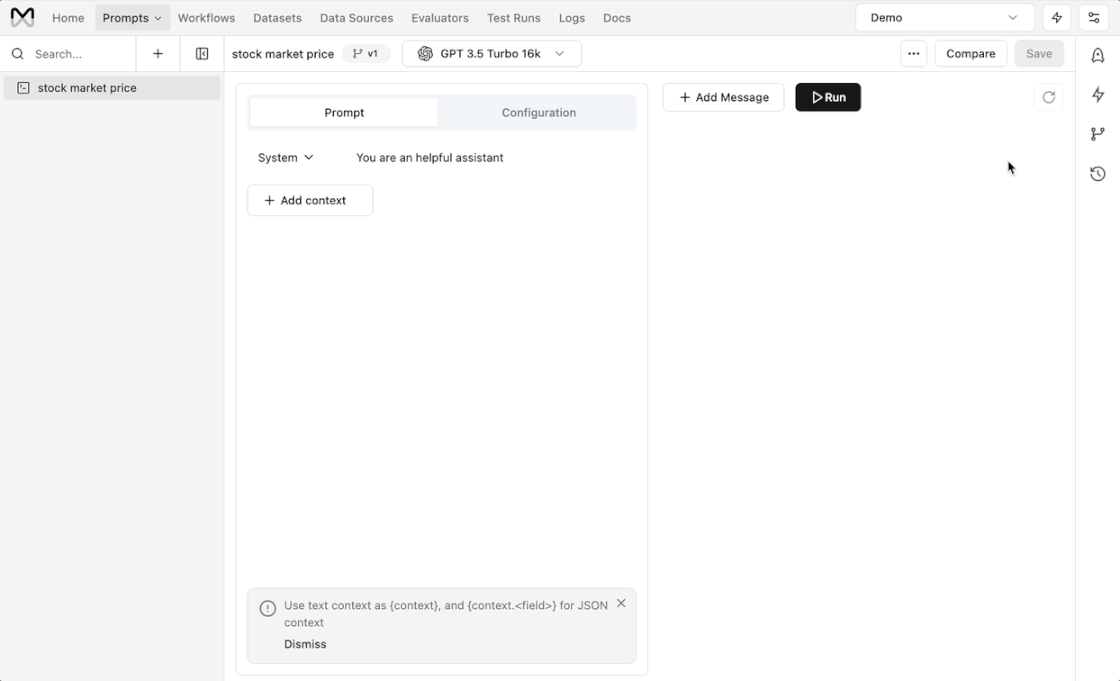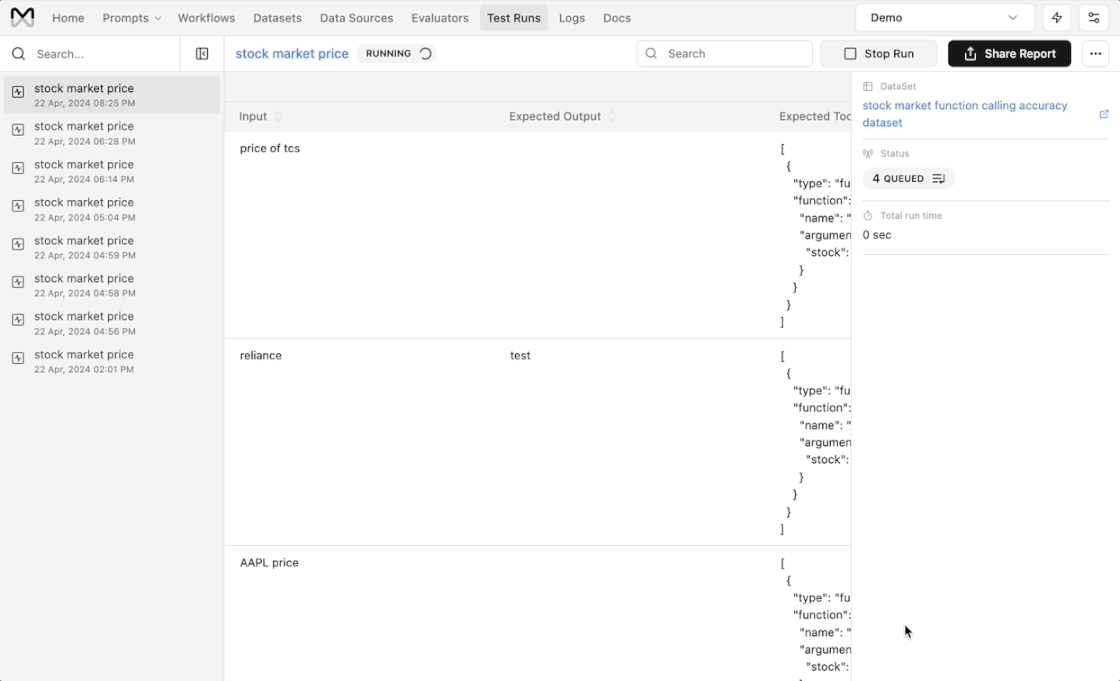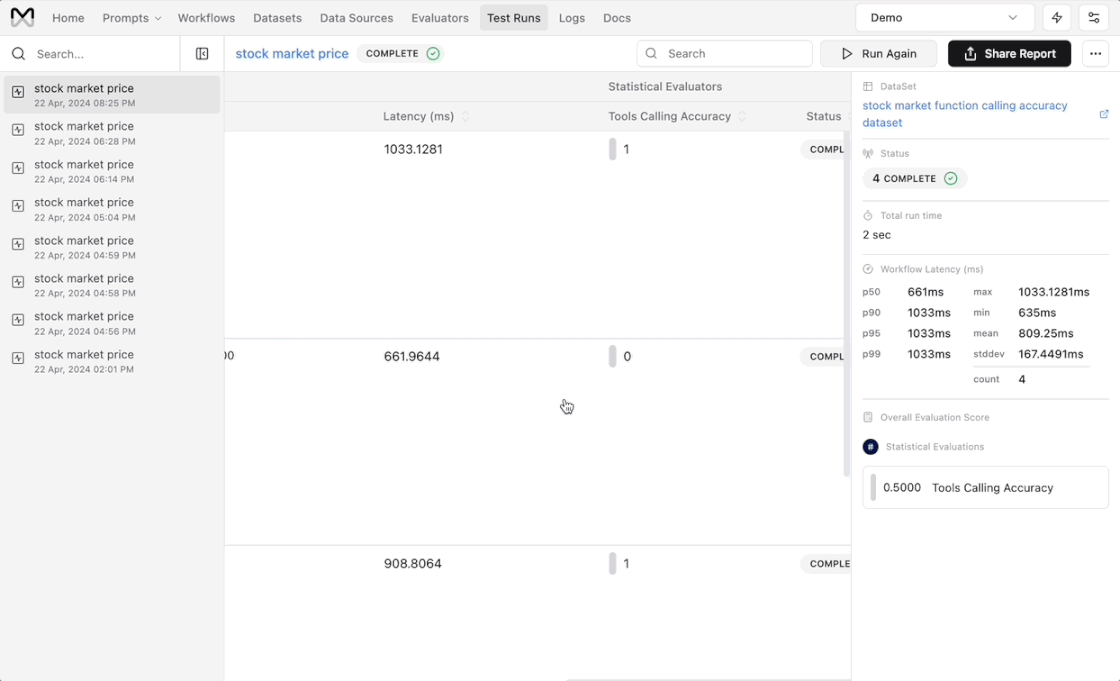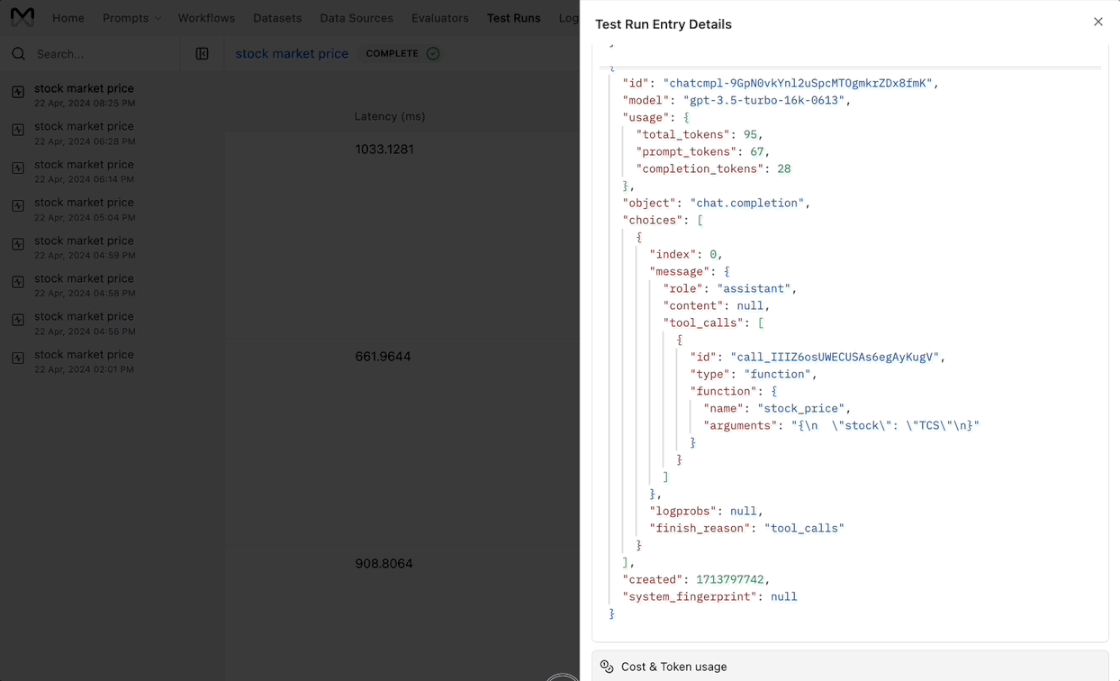
You can view the pass-fail result in the top section of Test Run Report